
word中如何检测单词拼写错误?
不知不觉中我发现,我比较喜欢从具体的应用场景来介绍一些技术。
而不是单纯的说技术,这不仅能引发我们的阅读兴趣,也能将我们所学的一些技术理解的更加透彻!
技术本身是没有价值的,只有把它用在了合适的地方产生了价值,它才有价值。
今天这篇,我们来说说 word 中是如何检测到单词的拼写错误的。如下图:

当单词拼写错误时,会用波浪线标记。尽管是一个很小不起眼的功能,但是你有没有想过这是如何做到的呢?
那咱们今天的主题就来了!哈希表或者散列表
哈希表简介
首先我们用一个例子来说明。拿excel表来说:
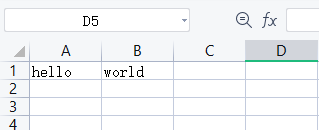
A1 坐标的值为 hello,A2 坐标的值为 world。
即是一个映射的关系。A1映射的值为 hello,A2映射的值为 world。
专业点的描述即为(来自百度百科):
哈希表(散列表),是根据关键码值(Key Value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中的一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数或者哈希函数,存放记录的数组叫做散列表或者哈希表。
给定表M,存在函数f(key),对任意给定的关键字值key,带入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希表,函数f(key)为哈希函数。
哈希函数
哈希函数,顾名思义就是一个函数,可以把它定义为hash(key),其中key代表元素的键值,hash(key)的值表示散列函数计算得到的哈希值(散列值)。
我们知道了哈希表的相关概念,那不得不考虑一个问题,这些数据它究竟是如何保存的呢?
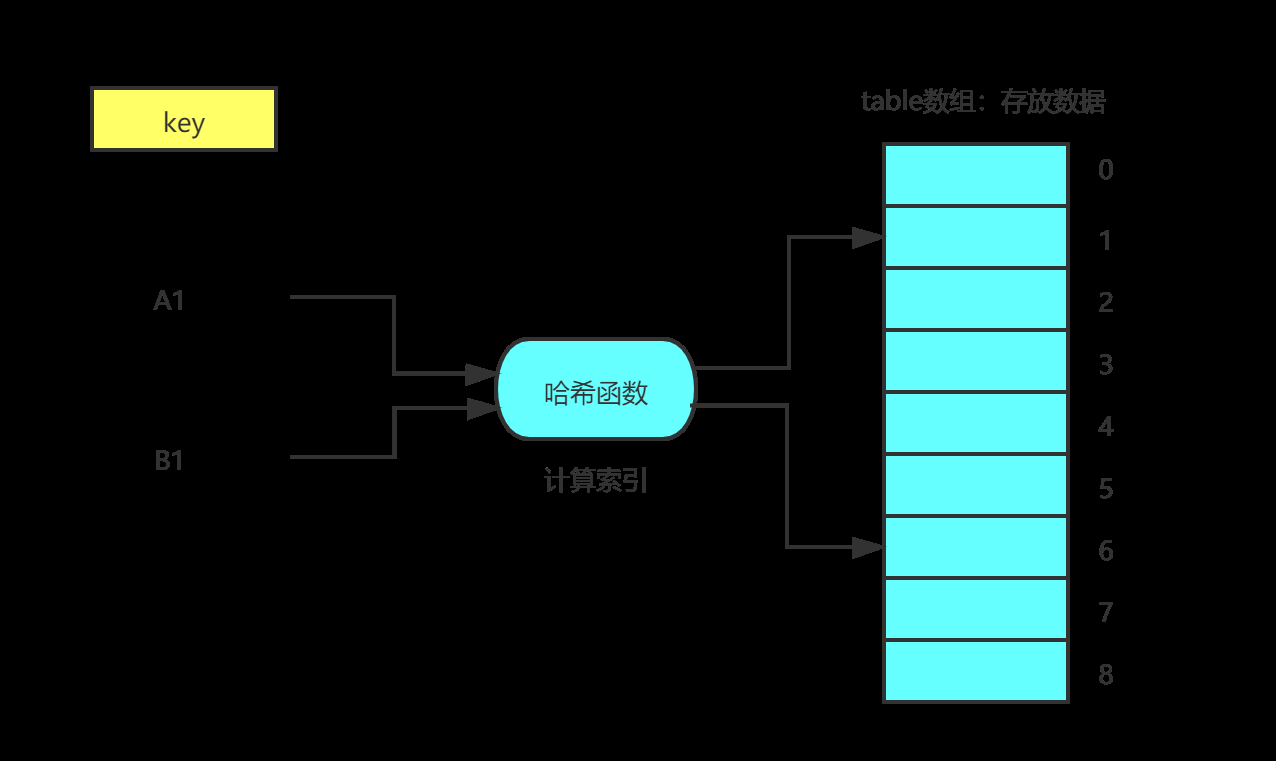
为了简单理解,用上述例子进行描述(只是为了好理解,实际可能并不是这样)。
A1中存储的值为"hello",B1中存储的值为"world"。即对于A1这个元素来说,"A1" 为key,"hello" 为 value。对于B1这个元素来说,"B1" 为key,"world" 为 value。
我们通过一个哈希函数,即hash(key),计算出一个随机索引值,我们将key对应的value存储到数组中。
如A1经过hash("A1")计算出的索引值为1,然后将A1对应的值存储到table[1]。
B1经过hash("B1"计算出的索引值为6,然后将B1对应的值存储到table[6]。
这样我们就完成了数据的存储。
经过上述研究,我们总结几点哈希函数需要满足的几个要求:
- 哈希函数计算得到的散列值是一个非负正数。
- 如果key1 = key2,那hash(key1) == hash(key2)
- 如果key1 != key2,那么hash(key1) != hash(key2)
假设哈希函数是$y = x^2$。
| x | y = $x^2$ |
|---|---|
| -1 | 1 |
| 0 | 0 |
| 1 | 1 |
第一点和第二点都可以理解,第三点是无法满足的,-1 != 1,但是计算出的结果均为1。
尽管说,第三点的要求看似合情合理,其实这是无法满足的。不同的key对应的散列值都不一样,几乎是不可能的。
业界注明的MD5,SHA等哈希算法,也无法完全避免这种冲突。
所以存储是有问题的,假如A1和B1经过hash(key)计算出来的散列值是一样的,那就产生了冲突,如下图:
那数据就无法得到正确的存储。
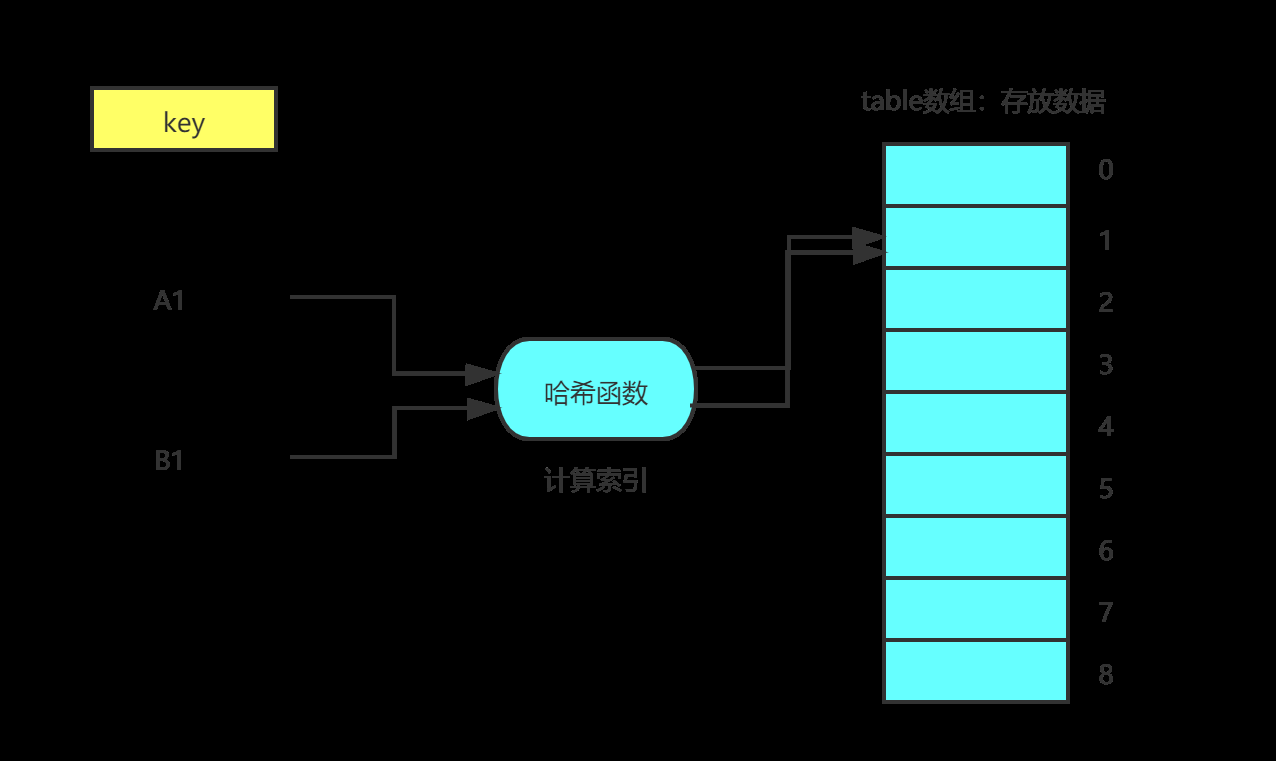
为了解决这种冲突,我们需要其他的途径。
解决哈希冲突
再好的散列函数也无法避免散列冲突。那究竟该如何解决散列冲突问题呢?我们常用的散列冲突解决方法有两类,开放寻址法(open addressing)和链表法(chaining)。
开放寻址法
开放寻址法的核心思想是,如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。
链表法
我们来着重讲解一下链表法。
当通过hash(key)计算出索引相同时,我们就建立一个单链表,将数据链起来。如下图:
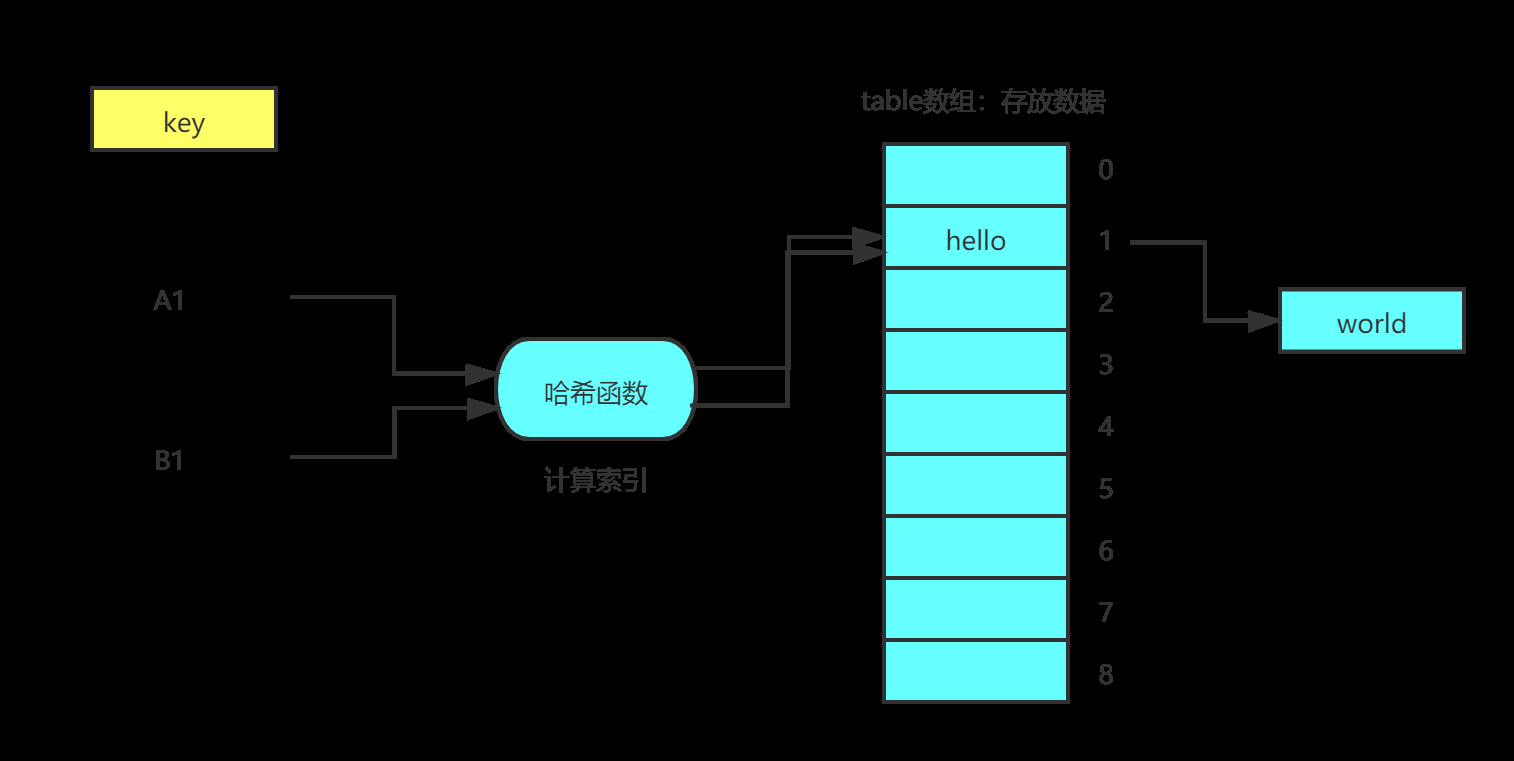
这样产生冲突之后,也可以很好的解决存储的问题了!
解答开篇问题
有了前面这些基本知识储备,我们来看一下开篇的思考题:Word 文档中单词拼写检查功能是如何实现的?
常用的英文单词有 20 万个左右,假设单词的平均长度是 10 个字母,平均一个单词占用 10 个字节的内存空间,那 20 万英文单词大约占 2MB 的存储空间,就算放大 10 倍也就是 20MB。对于现在的计算机来说,这个大小完全可以放在内存里面。所以我们可以用散列表来存储整个英文单词词典。
当用户输入某个英文单词时,我们拿用户输入的单词去散列表中查找。如果查到,则说明拼写正确;如果没有查到,则说明拼写可能有误,给予提示。借助散列表这种数据结构,我们就可以轻松实现快速判断是否存在拼写错误。
哈希表实战
为了更好的搞清楚哈希表的存储过程,我们来实现一个简易的hash表,我将参考redis的字典实现。
即使用的 set key value来进行存储,使用 get key获取对应的value。
那这就存在了一个问题需要进行解决。假如产生了冲突,如上图。那取数据就将存在一个问题,我们get A1取得的值怎么保证一定是hello,get B1的值怎么保证一定是world呢?这没法做到!
因此,我们需要在存储的时候把key也存储进去。那么我们就不能单纯的使用一个简单的数组进行存储了。
我们需要使用一个结构体数组。如下图:
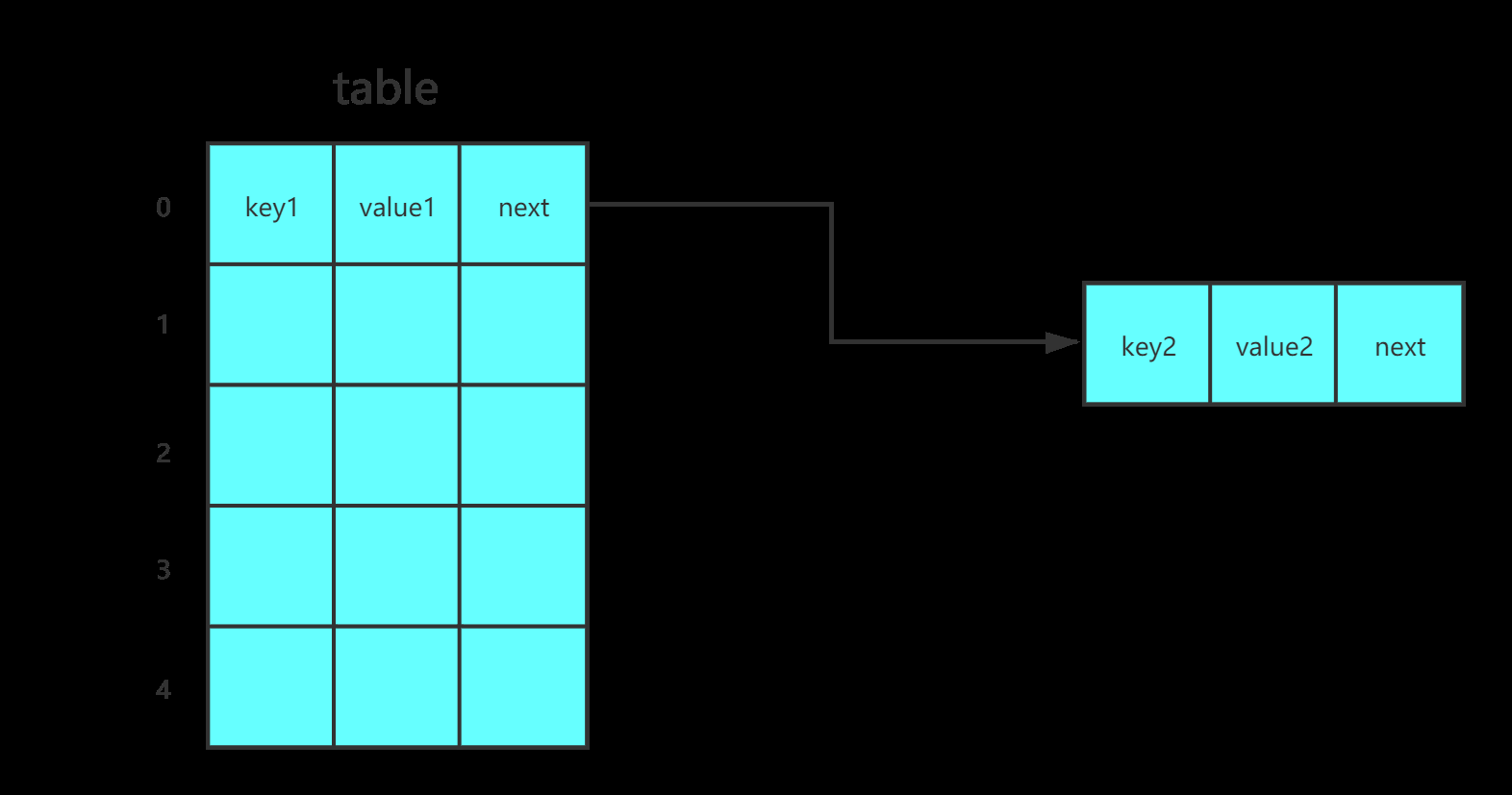
构建一个结构体数组,并将key,value,next作为一个结点保存在结构体中。
当查找元素时,通过hash(key)计算出索引,遍历链表,通过对存储的结点的value与查找的value比对,若相等,则返回该结点的value。
为了模拟出hash冲突,我们选用hash函数为 $y = x % 9$。
其中x为key的各位utf-8编码值相加之和。
对应代码如下(非常简易的实现):
为了模拟出hash冲突。我选择了两个key,"hello","d"。两个key计算出的hash值是相等的,均为1。
package main
import "fmt"
type dict struct {
hashTables [9]*hashTable
}
type hashTable struct {
node *entry
}
// 链表
type entry struct {
key, value string
next *entry
}
func main() {
dict := newDict()
dict.set("hello", "world")
dict.set("d", "d")
dict.set("ni", "hao")
fmt.Println(dict.get("hello")) // world
fmt.Println(dict.get("d")) // d
fmt.Println(dict.get("ni")) // hao
}
func newDict() *dict {
var hashTables [9]*hashTable
return &dict{hashTables}
}
func newEntry() *entry { return &entry{} }
func newHashTable() *hashTable {
node := new(entry)
return &hashTable{node}
}
// hashCode
func hashCode(key string) uint {
var code uint
for _, v := range key {
code += uint(v)
}
return code
}
// hash值
func hash(key string) uint {
return hashCode(key) % 9
}
// 设置键值
func (d *dict) set(key, value string) bool {
idx := hash(key)
ety := newEntry()
hashTab := newHashTable()
if d.hashTables[idx] != nil {
// 若冲突插入到链表头部
ety.key = key
ety.value = value
ety.next = d.hashTables[idx].node.next
d.hashTables[idx].node.next = ety
} else {
d.hashTables[idx] = hashTab
hashTab.node = ety
ety.key = key
ety.value = value
}
return true
}
// 取值
func (d *dict) get(key string) string {
idx := hash(key)
if d.hashTables[idx] == nil {
return ""
}
//遍历 hashTable
head := d.hashTables[idx].node
node := head
for node != nil {
// 找到需要查找的key,并返回对应的value
if node.key == key {
return node.value
}
node = node.next
}
return ""
}上述内容参考自 极客时间专栏 数据结构与算法之美。如果你也喜欢,可以订阅专栏哦,强烈推荐:





