
链表经典应用场景:LRU 缓存淘汰算法
“
或许很多人并不知道学习算法与数据结构到底有什么用,只是人云亦云。
哦算法与数据结构很重要,学就完事!
但是任何脱离实际应用的学习,都不能掌握其精髓!
所以我们需要通过具体的应用场景去分析使用哪个算法,使用哪个数据结构能够达到最好的效果。
在某些场景下需要用时间复杂度去置换空间复杂度,比如在一些小型硬件上,没有太多的存储资源,采用这种方式比较好。
而在某些性能要求高的场景下,则需要用空间复杂度去置换时间复杂度了。
所以呢我将创建一个系列,专门从实际应用的角度去讲解如何使用算法与数据结构。
第一篇就来说说链表。
首先问一个问题?学习链表有什么用呢?那就请带着这个问题阅读吧!
缓存
缓存是一种提高数据读取性能的技术,在硬件设计,软件开发中都有非常广泛的作用,比如常见的 CPU 缓存,数据库缓存,浏览器缓存等等。
缓存大小是有限的,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。
常见的策略有三种:
-
先进先出策略(FIFO,First In,First Out) -
最少使用策略(LFU,Least Rrequently Used) -
最近最少使用策略(LRU,Least Recently Used)
打个很形象的比喻。你买了很多的技术书,但有一天你发现,书很多,你要决定哪一本书要拿来垫显示屏。你会选择哪些书拿来垫显示屏呢?
像这样!

数组与链表
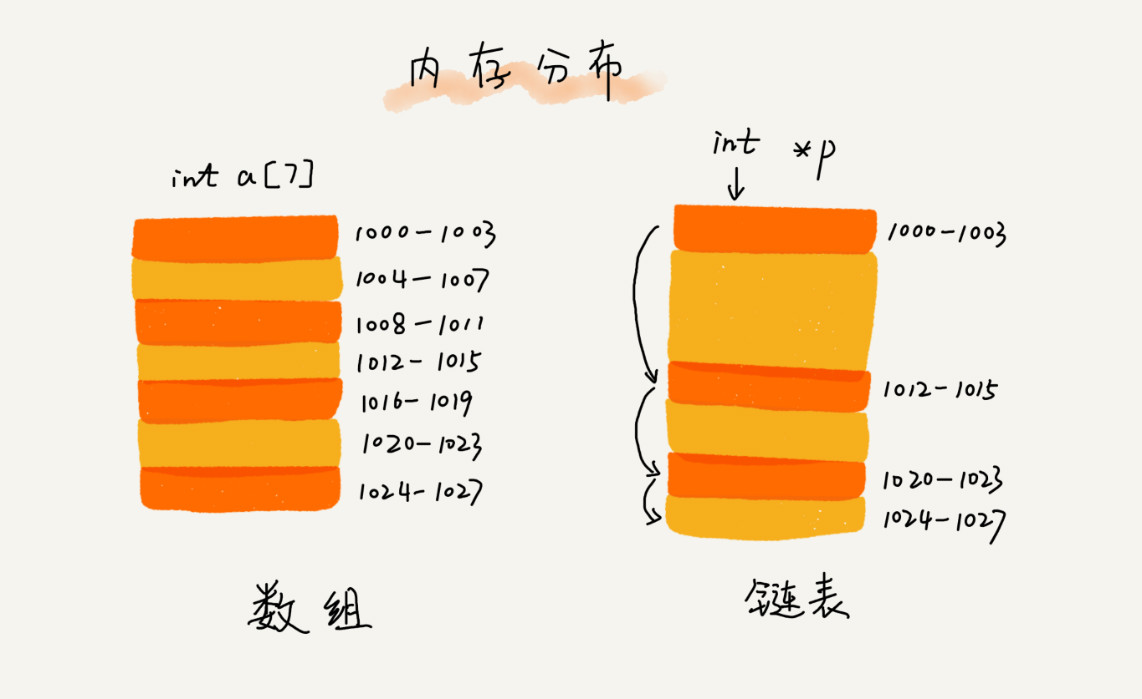
从底层的存储结构看,数组需要一块连续的内存空间来存储,对内存的要求比较高。如果我们申请一个 100MB 大小的数组,当内存中没有连续的,足够大的存储空间,即便内存的剩余可用空间大于 100MB,仍然会申请失败!
而链表不一样,它并不需要一块连续的内存空间,它通过指针将一组零散的内存块串联起来使用,所以我们如果申请的是 100MB 大小的链表,是不会出现问题的!
链表又分为:
-
单链表 -
循环链表 -
双向链表 -
双向循环链表
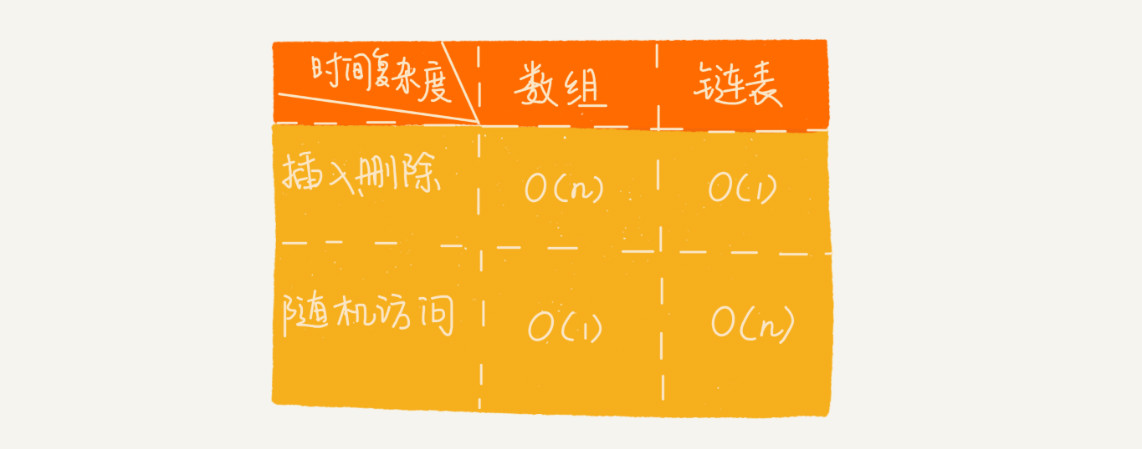
对于数组而言,随机访问的时间复杂度是 O(1),插入删除的时间复杂度是 O(n)。
而对于链表来说,不支持随机访问,只能遍历链表,所以时间复杂度是 O(n),但是插入删除的效率较高,为 O(1)。
但是数组和链表的对比,并不能局限于时间复杂度。而且在实际的软件开发中,不能仅利用复杂度分析就决定使用哪个数据结构来存储数据。
数组简单易用,在实现上使用的是连续的内存空间,可以借助 CPU 的缓存机制,预读数组中的数据,所以访问起来效率更高。
而链表在内存中并不是连续存储的,所以对 CPU 缓存不友好,没办法有效预读!
但是数组的缺点是大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配,将会导致 "out of memory"。
如果声明的过小,又会导致不够用的情况,所以数组的使用,一般当事先要能确定需要多大的空间。
链表则天然的支持动态扩容,这是与数组最大的区别。
用链表实现 LRU 缓存淘汰算法
由于需要多次删除插入数据,所以会使用链表这个数据结构。
思路:
维护一个有序单链表,越靠近链表尾部的节点是越早之前访问的。当有一个新的数据被访问时,我们从链表头开始遍历链表:
-
如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据对应的结点,并将其从原来的位置删除,然后插入到链表的头部。 -
如果此数据没有在缓存链表中,将分为两种情况: -
如果缓存未满,则将此结点直接插入到链表的头部。 -
如果缓存已满,需要先将链表的尾结点删除,再讲新的数据结点插入到链表的头部。
-
这样我们就用链表实现了一个最简单的 LRU 缓存。当然这种方式还是有缺陷。因为不管缓存有没有满,我们都需要遍历一遍链表,缓存访问的时间复杂度是 O(n)。我们可以继续优化这个实现思路,比如加上哈希表来记录每个数据的位置,将缓存访问的时间复杂度降到 O(1)。
golang 实现 LRU
package singleLinkedList
//单链表
type SingleLinkedList struct {
Head *Node
Length int
}
// 结点
type Node struct {
Data int
Next *Node
}
func New() *SingleLinkedList {
return &SingleLinkedList{NewNode(0), 0}
}
func NewNode(n int) *Node {
return &Node{Data: n, Next: nil}
}
//在某个结点后面插入结点
func (s *SingleLinkedList) InsertAfter(n *Node, d int) bool {
if n == nil {
return false
}
newNode := NewNode(d)
oldNext := n.Next
n.Next = newNode
newNode.Next = oldNext
s.Length++
return true
}
func (s *SingleLinkedList) InsertToHead(d int) bool {
return s.InsertAfter(s.Head, d)
}
func (s *SingleLinkedList) deleteNode(n *Node) bool {
if n == nil {
return false
}
cur := s.Head.Next
pre := s.Head
for cur != nil {
if cur == n {
break
}
pre = cur
cur = cur.Next
}
if cur == nil {
return false
}
pre.Next = n.Next
s.Length--
n = nil
return true
}
func (s *SingleLinkedList) DeleteNodeByData(d int) bool {
if !s.IsExist(d) {
return false
}
return s.deleteNode(s.locateNodeByData(d))
}
//通过 data 找到结点
func (s *SingleLinkedList) locateNodeByData(d int) *Node {
cur := s.Head.Next
for cur != nil {
if cur.Data == d {
//找到了数据,返回结点
return cur
}
cur = cur.Next
}
return nil
}
func (s *SingleLinkedList) DeleteTail() int {
cur := s.Head.Next
deleted := &Node{}
for cur != nil {
deleted = cur
cur = cur.Next
}
s.deleteNode(deleted)
return deleted.Data
}
func (s *SingleLinkedList) PrintList() []int {
res := make([]int, 0)
cur := s.Head.Next
for cur != nil {
res = append(res, cur.Data)
cur = cur.Next
}
return res
}
func (s *SingleLinkedList) IsExist(d int) bool {
cur := s.Head.Next
for cur != nil {
if cur.Data == d {
return true
}
cur = cur.Next
}
return false
}
package main
import (
"linkedList/singleLinkedList"
"log"
"sync"
"github.com/gin-gonic/gin"
"github.com/spf13/cast"
)
type LRUBuffer struct {
mu sync.Mutex
list *singleLinkedList.SingleLinkedList
bufferSize int
}
var lru = new(LRUBuffer)
func main() {
//创建一个缓存
lru.list = singleLinkedList.New()
//大小为10
lru.bufferSize = 10
r := gin.Default()
r.POST("/buffer", getBuffer)
if err := r.Run(":8080"); err != nil {
log.Fatal(err)
}
}
func getBuffer(c *gin.Context) {
d := c.PostForm("data")
//判断缓存中有没有这个数据
if lru.list.IsExist(cast.ToInt(d)) {
//有则删除这个结点
lru.mu.Lock()
defer lru.mu.Unlock()
lru.list.DeleteNodeByData(cast.ToInt(d))
lru.list.InsertToHead(cast.ToInt(d))
} else {
//如果缓存中没有这个数据
//1.缓存未满
if lru.bufferSize > lru.list.Length {
//添加数据到头部
lru.list.InsertToHead(cast.ToInt(d))
} else {
//缓存已满
//先删除尾结点,再插入头结点
lru.mu.Lock()
defer lru.mu.Unlock()
lru.list.DeleteTail()
lru.list.InsertToHead(cast.ToInt(d))
}
}
c.JSON(200, gin.H{
"data": lru.list.PrintList(),
})
}




